

هوش مصنوعی (Artificial Intelligence یا AI) و طراحی کارآزمایی بالینی دو حوزه جداگانه در علوم کامپیوتر و پزشکی هستند، اما ممکن است در برخی موارد به صورت ترکیبی مورد استفاده قرار بگیرند. در زیر به توضیح هریک از این حوزهها میپردازم.
هوش مصنوعی (AI): هوش مصنوعی به دنبال ساختن و توسعه سیستمهای کامپیوتری است که قادر به انجام کارهایی هستند که در ظاهر نیازمند هوش انسانی هستند. این فناوری شامل الگوریتمها، مدلها و تکنیکهایی میشود که بر اساس مفاهیمی مانند یادگیری ماشینی، شبکههای عصبی مصنوعی، پردازش زبان طبیعی و بینایی ماشین و غیره، برای حل مسائل پیچیده و انجام وظایف هوشمندانه استفاده میشود.در حوزه پزشکی، هوش مصنوعی به عنوان یک ابزار قدرتمند به منظور بهبود تشخیص، پیشبینی و درمان بیماران مورد استفاده قرار میگیرد. از مثالهای کاربردی هوش مصنوعی در پزشکی میتوان به تشخیص تصاویر پزشکی مانند سیتی اسکن و رادیولوژی، پیشبینی بیماریها و ارزیابی خطر ابتلا به بیماریهای مزمن، کمک به طراحی دارو و توسعه ترکیبات شیمیایی جدید و مدیریت دادههای بزرگ پزشکی اشاره کرد.
طراحی کارآزمایی بالینی: طراحی کارآزمایی بالینی در پزشکی به معنای طراحی و اجرای آزمایشهای بالینی است که به منظور ارزیابی اثربخشی و ایمنی درمانها، داروها یا روشهای پزشکی به کار میروند. در طراحی کارآزمایی بالینی، یک پروتکل مشخص برای اجرای آزمایش تعیین میشود و دادههای جمعآوری شده از بیماران مورد تحلیل قرار میگیرد تا نتایج علمی و قابل اعتمادی از اثربخشی درمان یا تفاوت میان گروهها به دست آید.اگرچه هوش مصنوعی میتواند در طراحی کارآزمایی بالینی نقشی مفید ایفا کند، مثلاً با استفاده از الگوریتمهای یادگیری ماشینی میتوان الگوهای پترنهای بزرگتر و روابط غیرخطی در دادههای بالینی تشخیص داد. همچنین میتوان از هوش مصنوعی در فرایند انتخاب و جذب بیماران، تولید دادههای مربوط به آزمایشها، تجزیه و تحلیل دادهها و تفسیر نتایج نیز استفاده کرد.
در این وبلاگ به بررسی نقش هوش مصنوعی در طراحی کارآزمایی بالینی می پردازیم.
انتخاب نامناسب بیماران و تکنیکهای جذب ضعیف، همراه با ناتوانی در مانیتورینگ و راهنمایی موثر بیماران در طول آزمایشات بالینی، دو عامل اصلی برای نرخ بالای شکست آزمایشات بالینی هستند. نرخ بالای شکست کارآزماییهای بالینی به طور قابلتوجهی به ناکارآمدی چرخه توسعه دارو کمک میکند، به عبارت دیگر روندی که علیرغم افزایش سرمایهگذاری در تحقیق و توسعه دارویی، کمتر به بازار میرسد. این روند برای دهه ها مشاهده شده و ادامه دارد.
تکنیکهای هوش مصنوعی به حدی پیشرفت کردهاند که امکان استفاده از آنها در شرایط واقعی برای کمک به تصمیمگیران انسانی وجود دارد. هوش مصنوعی این پتانسیل را دارد که مراحل کلیدی طراحی کارآزمایی بالینی را از آمادهسازی مطالعه به اجرا به سمت بهبود نرخ موفقیت کارآزمایی تغییر دهد، بنابراین بار تحقیق و توسعه دارویی را کاهش میدهد.
هوش مصنوعی میتواند قانون اروم (Eroom) رابه قانون مور (Moore) تبدیل کند
میانگین زمان و هزینهی لازم برای عرضه یک داروی جدید به بازار به ترتیب 10 تا 15 سال و 1.5 تا 2 میلیارد دلار است. تقریباً نیمی از این زمان و سرمایه گذاری در طول مراحل کارآزمایی بالینی چرخه توسعه دارو مصرف می شود. 50 درصد باقی مانده از هزینههای تحقیق و توسعه شامل کشف و آزمایشات پیش بالینی ترکیبات، و همچنین فرآیندهای تنظیمی است. این روند که در فناوری نیمههادیها، قانون مور نامیده میشود، قانون Eroom نامیده میشود. این روند همچنان ادامه دارد و تهدید جدیای برای مدل کسب و کار توسعه بالینی فعلی است. در عصر داروهای محبوب، نبود کارآمدی برای عرضه به اندازهای، پایدار نیست. یکی از موانع اصلی در توسعه دارو نرخ بالای شکست در آزمایشات بالینی است. کمتر از یک سوم ترکیبات فاز دوم به فاز سوم پیشرفت میکنند. بیش از یک سوم ترکیبات فاز سوم به تأیید نمیرسند. هزینه ناشی از هر آزمایش بالینی ناموفق حدود 0.8 تا 1.4 میلیارد دلار است. بنابراین، این موضوع به عنوان یک زیان قابل توجه در سرمایهگذاری در تحقیق و توسعه دارو محسوب میشود.
تصویر زیر چرخه توسعه دارو را نشان میدهد
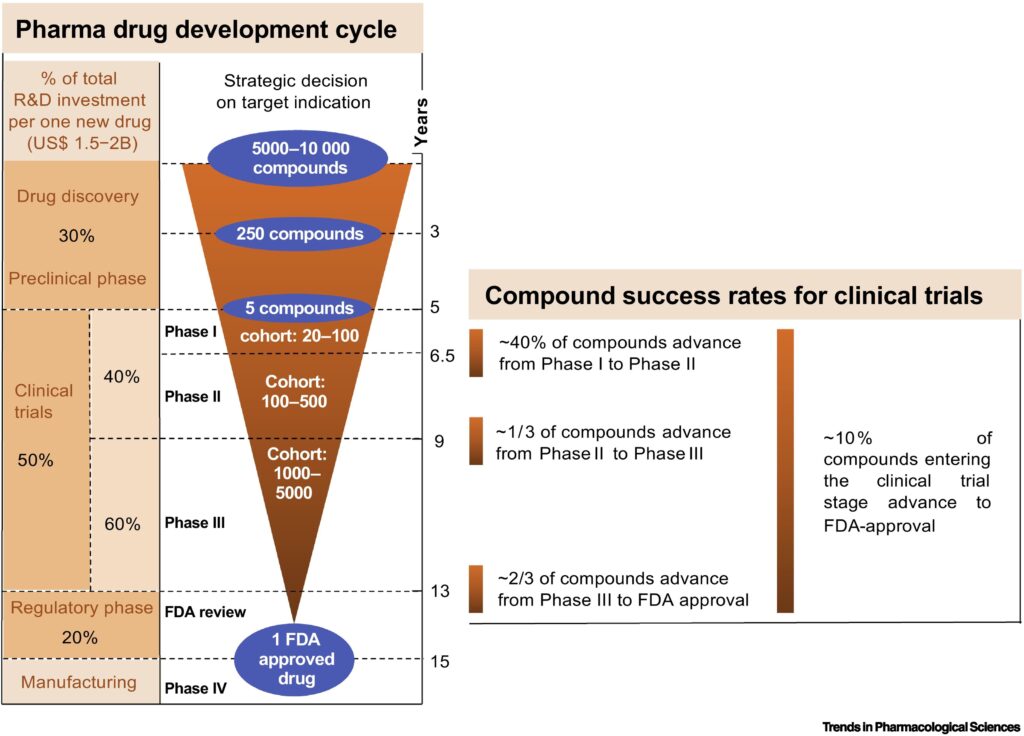
برای عرضه یک داروی جدید به بازار، تا 15 سال و سرمایهگذاری تحقیق و توسعه به میزان 1.5 تا 2 میلیارد دلار نیاز است. تقریباً نیمی از این سرمایهگذاری بر روی کارآزمایی بالینی صرف میشود و آزمایشات فاز سوم، پیچیدهترین و گرانترین آزمایشات هستند. احتمال موفقیت ترکیبات از مراحل کارآزمایی بالینی از یک فاز به فاز دیگر متفاوت است و تنها یکی از هر 10 ترکیب وارد کارآزمایی بالینی مشوند تا به تأییدیه FDA برسد. نرخ بالای شکست در کارآزمایی بالینی یکی از علل اصلی ناکارآمدی فعلی در دوره توسعه دارو است.
دو عامل اصلی که باعث شکست یک آزمایش بالینی میشوند، انتخاب نامناسب گروه بیماران و مکانیسمهای جذب که نمیتوانند به موقع بیماران مناسب را به آزمایش جلب کنند، و همچنین عدم وجود زیرساخت فنی برای مقابله با پیچیدگی اجرای یک آزمایش – به خصوص در مراحل بعدی آن – در غیاب سیستمهای قابل اعتماد و کارآمد برای کنترل پیوستگی، نظارت بر بیماران و تشخیص نقاط پایانی بالینی است. هوش مصنوعی (AI) میتواند به حل این نقاط ضعف در طراحی فعلی کارآزمایی بالینی کمک کند. یادگیری ماشین (ML) و به خصوص یادگیری عمیق (DL) قادرند الگوهای معنادار را به صورت خودکار در مجموعهدادههای بزرگی مانند متن، گفتار و تصاویر پیدا کنند. پردازش زبان طبیعی (NLP) قادر است محتوا را در زبان نوشتاری یا گفتاری درک و جمع آوری کند و رابطهای انسان-ماشین (human–machine interfaces (HMI)) امکان تبادل طبیعی اطلاعات بین کامپیوترها و انسانها را فراهم میکنند. این قابلیتها میتوانند برای جمع آوری مجموعهدادههای بزرگ و متنوع مانند پرونده سلامت الکترونیکی (electronic health records (EHR))، نظرات پزشکی و پایگاه دادههای آزمایشی برای بهبود تطابق و جذب کارآزمایی بیمار قبل از شروع کارآزمایی، و همچنین برای نظارت بر بیماران بهطور خودکار و مداوم در طول دوره استفاده شوند. این منجر به کنترل و ارزیابی قابل اعتماد و کارآمدتر نقاط پایانی آزمایش میشود. در بخشهای بعدی، نکاتی از طراحی کارآزمایی بالینی که قابلیت ورود به آنها برای هوش مصنوعی وجود دارد را برجسته میکنیم و روشهای خاص هوش مصنوعی که جالب توجه هستند و چگونگی استفاده آنها در بهبود عملکرد آزمایشات را توضیح میدهیم.
تصویر زیر استفاده از هوش مصنوعی (AI) برای طراحی کارآزمایی بالینی را نشان میدهد.
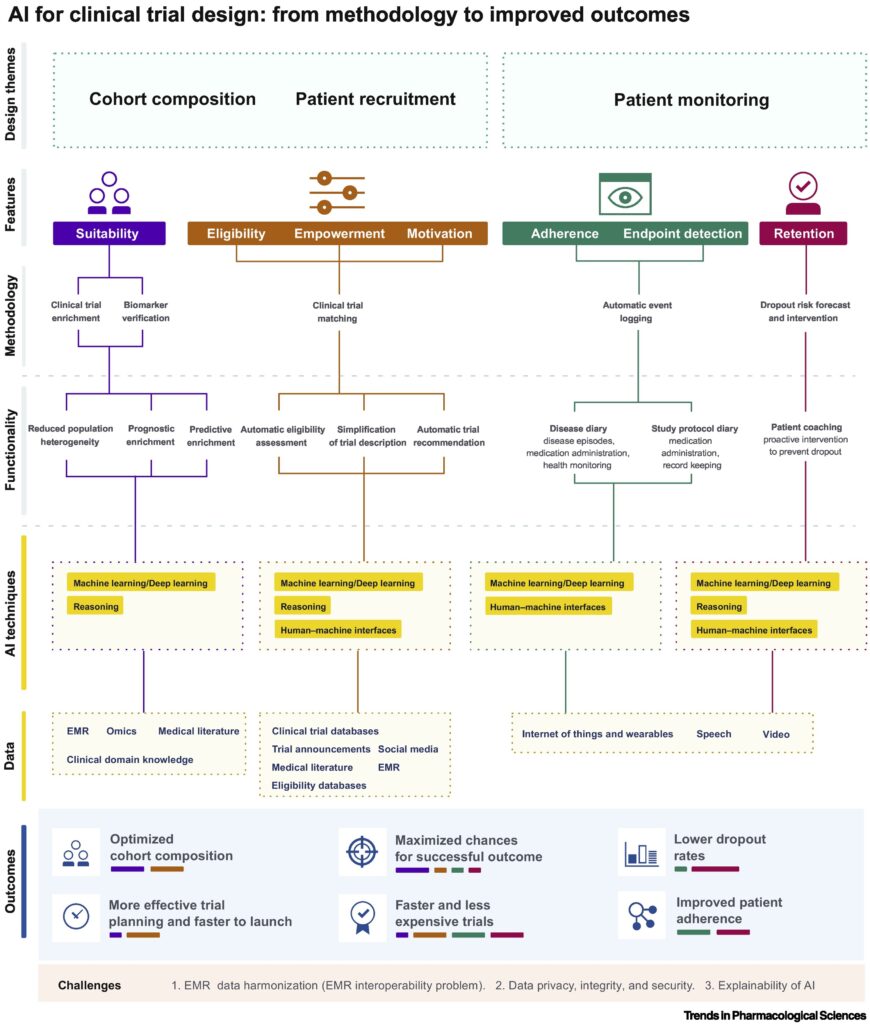
این تصویر راه های اصلی بهره برداری از هوش مصنوعی در فرایند طراحی کارآزمایی بالینی را نشان میدهد. سه موضوع اصلی طراحی (ترکیب گروه، جذب بیمار و نظارت بر بیمار (ردیف بالا)) بر اساس ویژگیهای بیمار در زمینه مناسب بودن، واجد شرایط بودن، توانمندسازی و ایجاد انگیزه در ثبت نام، و همچنین ویژگیهای آزمایشی از جمله تشخیص نقطه پایانی، کنترل پیروی و نگهداری بیمار است (ردیف دوم). انواع متدولوژی های طراحی (ردیف سوم) برای پیادهسازی قابلیتهای هدف استفاده میشوند (ردیف چهارم) . این قابلیتها از طریق ترکیبهای مجزا از سه فناوری اصلی هوش مصنوعی فعال میشوند: machine/deep learning, reasoning, and human–machine interfaces (ردیف پنجم) که هر کدام مجموعه خاصی از منابع داده خاص بیمار و عملکرد را تجزیه و تحلیل میکنند (ردیف ششم). بهبود نسبی که توسط این پیادهسازیها در نتیجه مطالعه به دست میآید توسط طول خطوط افقی در بارکد رنگی زیر جنبه های اصلی نتیجه (ردیف هفتم) نشان داده می شود. هر برنامه طراحی بر پایه هوش مصنوعی مستقیماً وابسته به کیفیت و مقدار دادهای است که میتواند به آن دسترسی داشته باشد و بنابراین با چالشهای اساسی مشابهی مواجه است (ردیف پایین).
Patient Selection
هر کارآزمایی بالینی الزامات فردی را برای بیماران شرکت کننده از نظر واجد شرایط بودن، شایستگی، انگیزه و توانمندی برای ثبت نام اعمال میکند. سابقه پزشکی یک بیمار خاص ممکن است او را غیرمناسب برای شرکت در آزمایش کند. یک بیمار واجد شرایط ممکن است در مرحلهای از بیماری نباشد، یا متعلق به یک زیر فنوتیپ (sub-phenotype) خاص باشد که توسط داروی مورد آزمایش هدف قرار می گیرد، بنابراین آن بیمار را نامناسب می کند. بیماران واجد شرایط و مناسب ممکن است به درستی برای شرکت در آزمایش انگیزه نداشته باشند، و حتی اگر هم داشته باشند، ممکن است از وجود آزمایش مطابقتی اطلاع نداشته باشند یا فرآیند جذب برایشان پیچیده و دشوار به نظر برسد. جلب تعداد کافی از بیماران در زمانبندی مشخص شده جذب، یک چالش بزرگ است و در واقع علت اصلی تأخیر در آزمایشها است.. 86٪ از آزمایشها زمانبندی جذب را رعایت نمیکنند و تقریباً یک سوم آزمایشهای فاز سه به دلیل مشکلات جذب، شکست میخورند. جذب بیماران به تنهایی یک سوم مدت زمان کل آزمایش را به خود اختصاص میدهد. به عنوان مثال، آزمایشهای فاز سه 60٪ از کل هزینههای مربوط به توسعه یک دارو از تمام مراحل آزمایش را شامل میشود زیرا بیشترین تعداد بیماران را نیازدارد. نرخ شکست 32 درصدی به دلیل مشکلات جذب بیماران در آزمایشهای فاز سه، یکی از نقاط ضعف طرحهای کارآزمایی بالینی را نشان میدهد: آن دسته از کارآزماییهایی که بیشترین تقاضای بیمار را دارند، بیشتر از تکنیکهای ناکارآمد جذب بیمار رنج میبرند. سیستمهای مبتنی بر هوش مصنوعی و ML میتوانند به بهبود ترکیب گروهی بیمار و ارائه کمک در جذب بیمار کمک کنند.
Cohort Composition
کارآزماییهای بالینی معمولاً برای نشان دادن اثربخشی یک درمان در یک نمونه تصادفی از جمعیت عمومی طراحی نمیشوند، بلکه هدف آنها انتخاب قبلی یک زیرمجموعه از جمعیت است که در آن اثر دارو، اگر وجود داشته باشد، به راحتیتر قابل نمایش است. این استراتژی به عنوان “clinical trial enrichment” شناخته میشود. اگر بیمار از قبل جزو زیرمجموعه مناسب نباشد، شرکت او در آزمایش به طور خودکار باعث کاهش اثربخشی داروی آزمایشی میشود. جذب تعداد زیادی از بیماران مناسب، موفقیت کارآزمایی را تضمین نمی کند، اما ثبت نام بیماران نامناسب احتمال شکست آن را افزایش می دهد.
در یک شرایط ایدهآل، ارزیابی مناسبت باید با استفاده از پروفایل genome-to-exposome تشخیصی ویژه بیمار به منظور تعیین اینکه آیا بیومارکرهایی که هدف دارو است در پروفایل بیمار به اندازه کافی نمایان میشوند یا خیر، صورت بگیرد. اگرچه آزمایشهایی که میتوانند از این رویکرد بهرهبرداری کنند زیرمجموعه نسبتاً کوچکی از کل آزمایشها را تشکیل میدهند، اما معمولاً همین آزمایشها هزینههای بالایی دارند، به خصوص زمانی که از تکنیکهای تصویربرداری پزشکی استفاده میشود. بنابراین، اگرچه در عمل ممکن است یک omic profile وجود نداشته باشد و نیاز به شناسایی بیومارکرهای مؤثر برای اکثر درمانهای در حال توسعه بالینی وجود داشته باشد، آزمون بیومارکرها همچنان باید در صورت امکان مدنظر قرار گیرد. روشهای تحلیلی پیچیده برای ترکیب دادههای اومیک با پرونده پزشکی الکترونیکی (EMR) و سایر دادههای بیمار، که در مکانها و فرمتهای مختلف پراکنده هستند – از نسخههای دستنوشته روی کاغذ تا تصویربرداری پزشکی دیجیتال – برای بهبود بیومارکرهایی که منجر به نقاط پایانی قابل اندازهگیری بهتر میشوند و در نتیجه شناسایی و توصیف زیرگروههای مناسب بیماران، ضروری هستند. این به فرصتی منحصربهفرد برای الگوریتمهای پردازش زبان طبیعی (NLP) و بینایی ماشین مانند OCR برای خودکارسازی خواندن و ترکیب این شواهد اشاره میکند. علاوه بر این، تعامل با دادههای از منابع و فرمتهای مختلف را به عنوان یک مجموعه داده یکپارچه برای تحلیل جامع آنها برای اهداف طراحی کارآزمایی بالینی، به ویژه در مورد دادههای EMR به دلیل حجم، سرعت، صحت و تنوع آنها بسیار چالش برانگیز است. ماهیت توجه به منبع دادههای مدلهای هوش مصنوعی، آنها را ابزاری منحصربهفرد برای هماهنگسازی دادههای EMR میکند که کلیدی برای طراحی ابزارهای کارآزمایی بالینی و کشف بیومارکرها است. با این حال، باید مراقبت بود که از overfitting در مدلهای یادگیری ماشین به علت عدم تعادل در دادههای آموزش، جلوگیری شود.
مدلها و روشهای هوش مصنوعی میتوانند با کمک یک یا چندین روش شناسایی شده توسط سازمان غذا و دارو (FDA)، انتخاب گروه بیماران را بهبود بخشند: 1- کاهش تنوع جمعیت، 2- انتخاب بیمارانی که احتمالاً دارای یک نقطه پایانی بالینی قابل اندازهگیری هستند که به آن “prognostic enrichment” نیز گفته میشود، و 3- شناسایی جمعیتی که بیشترین قابلیت پاسخ به درمان را دارند، که به آن “predictive enrichment” نیز گفته میشود. فنوتایپسازی الکترونیکی، یک رشته مطالعاتی تثبیت شده در انفورماتیک سلامت است که بر کاهش تنوع جمعیت تمرکز میکند و فرایند شناسایی بیماران با ویژگیهای خاصی که قابل توجه هستند را شامل میشود. این ویژگیها میتواند به سادگی بیماران مبتلا به دیابت نوع ۲ باشد، یا به پیچیدگی بیماران مبتلا به سرطان پروستات باشد. وظیفه فنوتایپ الکترونیکی بسیار چالش برانگیزتر از جستجوی ساده است و به روش های پیچیده ای نیاز دارد تا ناهمگونی را در میان سوابق بیمار، در میان انواع داده های متعدد، و برای استفاده از نمایش های پیچیده دانش حوزه بالینی در نظر بگیرد. اگرچه روشهای اولیه متکی بر قوانین دستساز برای موارد ساده مؤثر بودند، اما ثابت کردند که برای موارد پیچیدهتر و ظریفتر ناکافی هستند. در سالهای اخیر، تلاشهای فزایندهای برای طراحی طیف متنوعی از روشهای ML، از NLP گرفته تا استخراج قوانین مرتبط تا DL صورت گرفته است، که پیشرفت زیادی در جهت توانایی در مدیریت موقعیتهای پیچیده دنیای واقعی نشان داده است.
Assistance in Recruitment